Recommendations Systems and Understanding SVD & Funk-SVD
A recommendation engine is a powerful tool that uses machine learning algorithms to suggest items to users based on their past behaviour and preferences. It uses data mining techniques to analyze patterns in consumer behavior data and make personalized suggestions. In simple terms, it helps to filter through a vast amount of data to provide the most relevant options to the user by recommending products, services, or content that they might be interested in based on their browsing and buying history.
Recommendation systems generally fall into two main categories: Knowledge-based and Content-based recommendation engines.
I ) Knowledge-Based Recommendation Systems:
These systems use explicit knowledge about user preferences to make recommendations. For instance, a user might select their preferred genres from a dropdown menu, and the system will recommend the top 10 movies in those genres.
Collaborative Filtering: Collaborative filtering is a method of making recommendations based on the interactions between users and items. It assumes that if two users have liked the same items, one user might enjoy another item the other user liked. As an example, we can assume that we have two different users whom watched and liked same movies, and we offer the user2 another movie that user1 liked.
A) Neighborhood-Based Collaborative Filtering:
This method involves calculating the similarity between users or items. There are various ways to measure similarity:
- Pearson’s Correlation Coefficient: Measure related to the strength and direction of a linear relationship. If we have two vectors “ X & Y”, we can compare their individual elements in the formula to calculate Pearson correlation coefficient, with the formula below.
mean_x, mean_y = np.mean(x), np.mean(y)
x_diffs, y_diffs = x - mean_x, y - mean_y
corr_coef = np.sum(x_diffs * y_diffs)/(np.sqrt(np.sum(x_diffs**2))*np.sqrt(np.sum(y_diffs**2)))- Spearman’s Correlation Coefficient: Known as “non-parametric” statistic, meaning its statement doesn’t depend parameters (parametric example; Normal distribution, Binomial distribution). Unlike Pearson, Spearman’s Rank Correlation uses the ranks of data points rather than the raw data. You can use the
.rank()function in Python code above to implement it. In python we can use .rank( ) function. Same formula with Pearson, but only thing change is x_rank is used. Only add the following code behind the Pearson.
x, y = x.rank( ), y.rank( )
# The rest of the code is same with Pearson's Correlation Coefficient.Other methods for measuring similarity include:
- Kendall’s Tau
- Euclidean Distance
- Manhattan Distance
B) Similarity-Based Collaborative Filtering:
This approach uses ratings from similar users to influence the recommendations. The steps include:
- Removing items the user has already seen.
- Finding highly rated items from similar users.
- Recommending items that meet the criteria above.
II ) Content-Based Recommendation Systems:
Content-based recommendation is a type of recommendation system that suggests items to users based on their past preferences and behavior. The system analyzes the content or attributes of items that a user has liked in the past and uses this information to recommend similar items. For example, if a user has a history of watching romantic movies, a content-based recommendation system may suggest other romantic movies to the user.
Singular Value Decomposition(SVD):
Singular value decomposition, commonly known as SVD, mathematical technique used to decompose a matrix into three matrices. The goal of this technique is to find the best set of factors that can be used to represent the matrix with the most accurate predictions. In simple terms, it helps to filter and extract hidden structure through a vast amount of data to provide the most relevant options to the user.
U Matrix: Represents user preferences for latent features.
Σ Matrix: Contains weights that show how much each latent feature matters in reconstructing the original matrix.
V Matrix: Represents how items relate to each latent feature.
By multiplying these matrices, you can predict how users will rate items based on their preferences. ( U * Σ * V )
Latent Factor: Latent factors are hidden features inferred from the data. For instance, in a movie recommendation system, latent factors might include the genre, the presence of certain actors, or specific themes. These factors, although not directly observed, are crucial for making accurate predictions.
How SVD Works?
To be start with, we need to understand that this approach is helping us in making recommendations, and it is only works when our user-item matrix has no missing values. In this part, we start with dataset contains no missing values as our first step.
We mentioned that we decompose a matrix into three matrices.
The formula is A = U * Σ * V (Transpose)
U = Matrix that provides how users feel about latent features.
Σ = A matrix that provides weights in descending order with how much each latent feature matters towards reconstructing the original user-movie matrix.
V = Matrix that provides how move relate to each latent feature.
k = the number of latent features used (dogs, ai, happiness)
n = The number of users
m = The number of movies
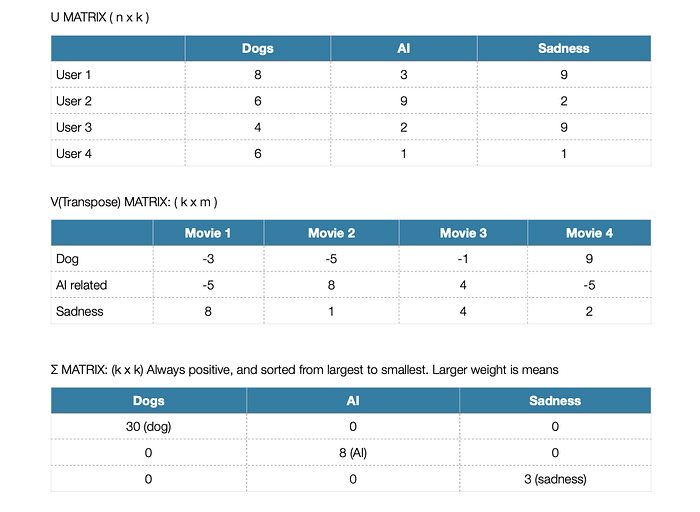
By multiplying these matrices together, we are reconstructing each user-movie combination based on how the users feel about the latent factors (U), how much each latent features matters in predicting a rating (Σ), and how a latent feature appears in a movie (V transpose). After that, we can find a prediction for every user-movie combination.
Note: We can keep as much as latent feature and find their weights with the following formula.
30**2 + 8**2 + 3**2 = 973 and we can find each feature’s ratio with dividing their square such as 30**2 / 973
When to use and avoid SVD?
SVD is very good method when we have no missing value in our dataset. We can use SVD when we try to reducing the dimension of data, recommendation systems, NLP etc. It is important that we have no missing values in our data. In case of we have missing values, we can find these values with using FunkSVD methodology.
A downside of using SVD is that it utilizes a single dataset and by default doesn’t include any other relevant information that could be incorporated in the dimension reduction. Note that, it is not efficient to use SVD when we dealing with very large metrics, non-linear data, categorical data, missing data, correlated variables.
FUNK Singular Value Decomposition(Funk SVD):
Funk SVD comes in to field when we practice a real-time problems with high quantity of ‘NaN’ values. Based on an example we argued in SVD, most of the users don’t prefer to rate the movie they watch, thus, we need to use solution-based approaches to our problems.
Basically, what Funk SVD does is the approach to the SVD formula, but fills the ‘NaN’ values to randomly generated values. Let’s analyze this function step by step:
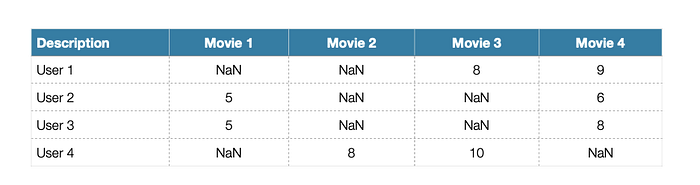
- Assume that we are dealing with the same data as SVD, but we have some missing values in the dataset. We generated U (user — latent features) and V Transpose (latent features — movies) but keep their values same as SVD, but we generated these values randomly.
- When we try to predict the possible score of Movie-3 given by User 1, which the real score is 8, we take U matrix as [ 8 , 3 , 9 ] for ‘User by Latent Features Vector’.
- Then we get the V Transpose (‘Latent Features — Movie’) vector we randomly generated before, which is [ -1 , 4 , 4 ].
- Multiplying these two vectors gives us the ‘Dot Product’ between row and column.
(8 * -1) + (3 * 4) + (9 * 4) = 40 which shows our prediction score. After finding this, we calculate the error with the (real value — prediction)² formula. ( 8–40 )² = 1024
- High note and real calculation comes in this step. To decrease this error rate, we use ‘Gradient descent’, also known as ‘learning rate’ with ‘ a ‘ in the formulas below. One formula for U vector, other is the V vector.
U Vector → U + a * 2 (real value — prediction) * V
V Vector → V + a * 2 (real value — prediction) * U
In case of our example, we assume the gradient descent ( a ) as 0.1 and apply the formula with it.

Let’s update the second value (3) of U and V vector for ‘Dogs’ feature with the ‘gradient descent’ formulation.
A) New U Value for User1-Dogs vector = 8 + 0.1 * 2 ( 8–40 ) * (-1) = 14.4
B) New U Value for User1-AI vector = 3 + 0.1 * 2 ( 8–40 ) * (-1) = 9.4
C) New U Value for User1-Sadness vector = 9 + 0.1 * 2 ( 8–40 ) * (4) = -16.6
— — —
A) New Vt Value for User1- Dogs vector = -1 + 0.1 * 2 ( 8–40 ) * 8 = — 52.2
B) New Vt Value for User1- Dogs vector = -1 + 0.1 * 2 ( 8–40 ) * 3 = — 20.2
C) New Vt Value for User1- Dogs vector = 4 + 0.1 * 2 ( 8–40 ) * 9 = 24.8
This calculation is a very first step of our error minimization step. Changing these values in our U and Vt matrixes will help us the way to find the best ‘gradient descent’ metric on the way to minimization of error and potentially reaching more accurate predictions.
When to Avoid Funk SVD?
Funk SVD assumes that there is some prior information about users’ preferences, but if there is not enough data about a new user, the recommendations may not be reliable.
