Web Content Mining with SVM Kernels and Support Vector Machines:
Web structure mining involves analyzing the organization and layout of a website. This type of analysis provides valuable insights into how users interact with a website and can help identify areas for improvement. Python-based web frameworks, such as web2py, Flask, and Django, can be used for web structure mining. These frameworks are designed for developing web applications and can also be used for analyzing website structure.
Web Structure Mining Techniques: “Link-based Classification”, “Link-based Cluster Analysis”, “ Link Type”, and “Link Strength”.
Web Structure Mining Algorithms:
• Page Rank Algorithm
• HITS algorithm(Hyperlink Inc.Topic Search)
• Distance Rank Algorithm
• Eigen Rumor Algorithm
• Time/Tag Rank Algorithms
• Weighted Rank Page Algorithm
Web Usage Mining:
Web usage mining, on the other hand, is focused on understanding user behavior on a website. This is achieved by analyzing server log files and can be done using tools such as Google Analytics, Adobe Analytics, and Piwik. Google Analytics and Adobe Analytics are web analytics services that provide detailed information about website traffic and user behavior, while Piwik is an open-source web analytics platform that can be customized to track specific metrics.
Data Processing and Pattern Discovery:
Preprocessing of data is also an important step in web mining. Tools such as Sumatra TT and SpeedTracer can be used for this purpose. After preprocessing, the data can then be used to discover patterns and analyze them with other tools. The open-source programming language Python has various libraries and tools that are useful for web mining, making it a flexible and handy choice for data scientists and web developers.
Web Usage Mining Techniques: “Data Preprocessing”, “Data Pattern Discovery”, “Pattern Analysis”.
Web Usage Mining Algorithms:

Web Content Mining:
Web content mining is a technique used to extract useful information from the web, such as text, images, and videos. This process is often performed by search engines. Two main approaches to web content mining are the “Agent-Based” approach, and the “Data-Based” approach.
In the “Agent-Based” approach, there are three types of agents: “Intelligent Search Agents”, “Information Filtering/Categorizing Agents”, and “Personalized Web Agents”. Intelligent search agents; automatically search for information based on a specific query and use characteristics and user profiles. Information agents; use various techniques to filter data based on predefined instructions. Personalized web agents learn user preferences and discover documents related to those user profiles.
The “Data-based Approach” involves the use of a well-formed database containing schemas and attributes with defined domains. Web content mining can become complex when it involves extracting information from “unstructured”, “structured”, “semi-structured”, and “multimedia” data.
Cross Validation:
Before explaining what SVM is, we need to be familiar with the terms, “Cross Validation”. Let’s try to understand it with an example.
Assume that we have cancer cells weather classified as malignant or benign. The shortest distance between the observation and the threshold called the margin. The distance between the observation and the threshold are the same and both reflect the margin. So, if we declare the margin here, the margin would as largest as it can be. If we move threshold closer to the left, the distance between the benign observation and the threshold would get smaller, and the margin get smaller. When we use the threshold that gives us the largest margin to make classifications, we are using maximum marginal classifier. But following to that, we also need to know that they are too sensitive to outliers and can cause miscalculation. To make threshold that is not so sensitive to outliers, we must allow misclassifications.
Choosing a threshold that allows misclassifications is an example of the Bias/Variance Tradeoff. When we allow misclassifications, the distance between the observations and the threshold is called a Soft Margin. So the question is, even if we know the outliers, how we know if the best soft margin is between the closest malignant and benign observations or can it be any other pair.
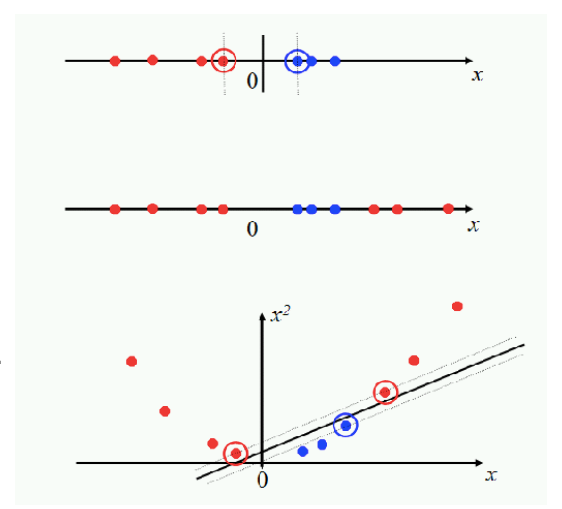
We use Cross Validation to determine how many misclassifications and observations to allow inside of the Soft Margin to get the best classification. When we use a soft margin to determine the location of the threshold, we are using a Soft Margin Classifier, in other words, it’s called Support Vector Classifier to classify observations. The name comes from the fact that the observations on the edge and within the Soft Margin are called Support Vectors.
So, if we had another aspect, such as age, and weight, the data would be two dimensional. When the data is two dimensional, the Support Vector Classifier is a line, and the soft margin is measured between the closest two observations, seen in the third graph below. If the data had three dimensional, then the vector would behave as a plane instead of the line, and the observation can be shown as their size as the third dimension (think that as a country wealth with the population and the bubble chart).
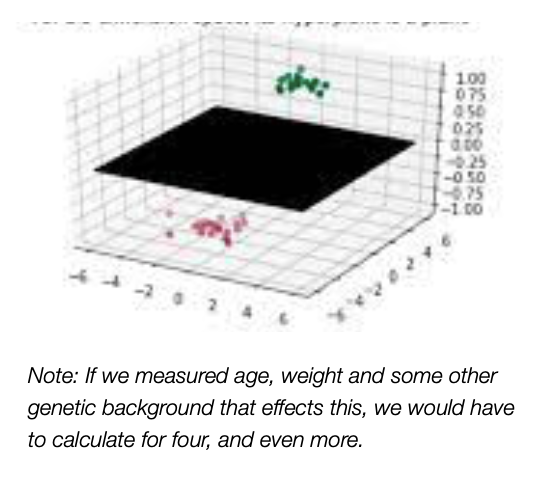
So far, we understand that if we have one dimensional data, Support Vector Classifier act as a point, if we have two dimensional space, it acts like a vector, and for three dimensional data, it acts like a flat affine ‘2-dimensional subspace’. And for 4 or more dimensions, support vector classifier isa Hyperplane (also called flat affine subspace).
But the problem with support vector classifiers starts when the data something like the middle of the “Image 2” provided.
Support Vector Machine (SVM):
SVM come to the field when we have this kind of dataset (Image2). Lets think that we have data that like the second picture when the patient get cured if they use the right dosage and not hill if they overdose or lower dose that it needs to be. In that case, we have some approach to take this data into one dimension to two dimension with different approaches. This might be by squaring it or, or calculating its cube. Support vector classifier separates the higher dimensional data into two groups.
So, how do we decide how to transform the data from one dimensions into two. In order to make the mathematics possible, and find the best approach, Support Vector Machines use something called Kernel Functions to systematically find Support Vector Classifiers in higher dimensions.
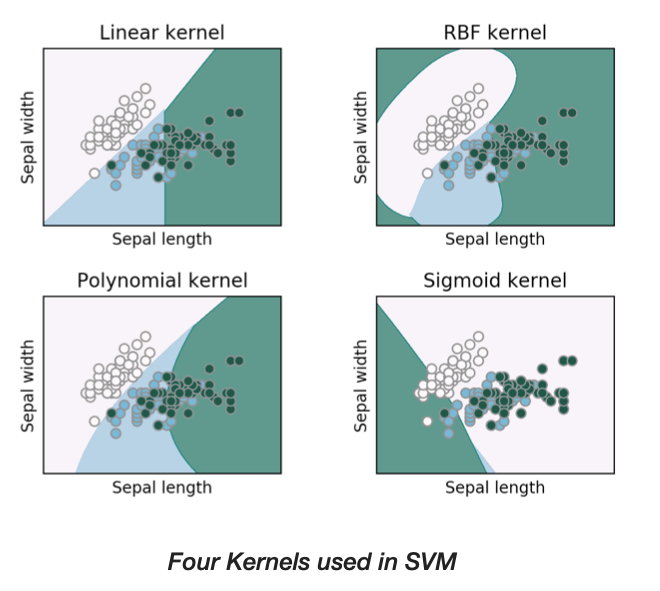
The Kernel Trick: The examples we observed show the data being transformed from a relatively low dimension, to a higher dimension. Kernel functions only calculate the relationship between every pair of points as if they are in the higher dimensions, they don’t actually do the transformation. This trick, calculating the high-dimensional relationship without actually transforming the data to the higher dimension is called The Kernel Trick. This reduces the amount of computation required for SVMs by avoiding the math that transforms the data from low to high dimensions, and it makes calculating relationship in the infinite dimensions used by the Radial Kernel possible. There are two Kernel generally used in “text processing” and “image processing”.

Polynomial Kernel: The kernel has the parameter *d’, which stands for the degree of the polynomial. When d=2, we get 2nd dimension based on dosage square. Polynomial Kernel compute the 2 dimensional relationship between each pair of observations. If we set d=3, we would get the dimensions for the cube of dosage. In here, we can use “Cross Validation” to find a good value for d.
Radial Kernel: Also called Radial Basis Function (RBF) Kernel. This is a different approach to observations, and behaves like a Weighted Nearest Neighbor model. The reason I say this is because the closest observations (nearest neighbors) have a lot of influence on how we classify the new observation. And the observations that are further away have relatively
little influence on the classification. Since these observations are the closest to the new observation, the Radial Kernel uses their classification for the new observation.
HOW SVM WORKS IN WEB CONTENT MINING?
The study has presented (Image 4) a novel approach to infer restaurant styles from user uploaded photos on user-review websites. The approach involves a deep multi-instance multi-label learning (MIML) framework that leverages the use of Convolutional Neural Networks (CNNs) and Support Vector Machines (SVMs). The framework starts by collecting a restaurant photo dataset and trains a multi-label CNN in two rounds in a bootstrap fashion. The trained multi-label CNN is then used to extract
restaurant style features and the features are fed to a set of SVMs to obtain the restaurant styles. The study has shown that the proposed approach is effective in predicting the style tags of a restaurant with a F-1 score of 0.58. The approach also demonstrates that the performance of the approach increases as the number of photos of a restaurant increases. The study provides insights into the use of CNNs and SVMs in web content mining and highlights the potential of these techniques in classifying
images and restaurants.

The SVM algorithm has demonstrated its effectiveness in solving complex classification problems by finding the optimal hyperplane that separates the data into different classes. Furthermore, researchers have combined SVM with deep learning techniques, such as “Convolutional Neural Networks (CNNs)”, to improve the performance of the classifier for image classification tasks. In conclusion, SVM is a robust and versatile algorithm that continues to be an active area of research and widely applied in web content mining, particularly for image classification.
References:
I) Web Content Mining: Johnson, F., Gupta, S.K., Web Content MiningsTechniques: A Survey, International Journal of Computer Application. Volume 47 — №11, p44, June (2012). (https://research.ijcaonline.org/ volume47/number11/pxc3880266.pdf)
II) (https://thesai.org/Downloads/Volume9No6/Paper_30-Data_Mining_Web_Data_Mining_Techniques.pdf)
III) SVM Graph: https://www.google.com/url?sa=i&url=https%3A%2F%2Fnlp.stanford.edu%2FIR- book%2Fhtml%2Fhtmledition%2Fnonlinear-svms-1.html&psig=AOvVaw1EuhE6tM2Tqlh8l- E51jiN&ust=1674877345027000&source=images&cd=vfe&ved=0CBAQjRxqFwoTCOi4mLzq5vwCFQAAA AAdAAAAABAJ
